
Community Call – AI Series | Leveraging Open-Source AI Models for Text, Audio, and Images
The second episode in the recent AI series hosted by GIG, has furthered our conversation and understanding of the AI phenomenon. This episode focused on the inner workings of AI. Through this understanding, we can then be better informed about AI usage. To assist our understanding, we were joined by Adriano Belisario from the Joint Data Centre on Forced Displacement and Eric Nitschke from Wakoma who outlined what exactly AI is and how we can make the most of open-source options.
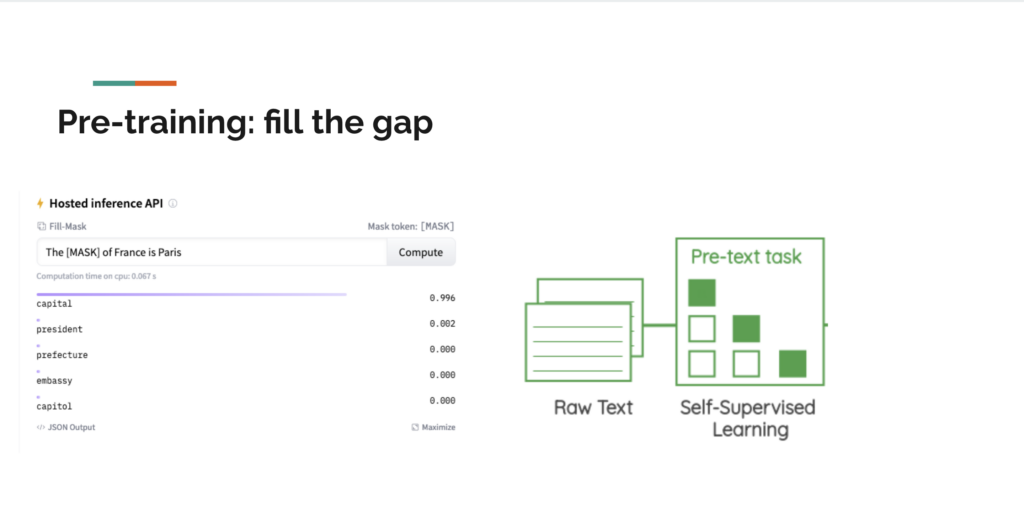
AI models do not just exist. Many steps are enacted and an abundance of data is required to create an AI model. First, we must go through pre-training which is when the AI model is exposed to an abundance of data without any specific tasks or labels. This is when the AI model is making sense of the data. This is through embeddings which are a number sequence as long as 12k digits. This number sequence works as a semantic coordinate which the model uses so it can place the word. This functions in a contextual environment where words are placed based on their relationships to other words. For example, the word Lion appears more often with Tiger so their coordinates are closer as opposed to Lion and Mathematics. This proximity and relationship is what gives the words meaning within the model. Thanks to the Word2Vec (2013) research paper this knowledge is open source. Once this is done, a fill-the-gap exercise is conducted to test the accuracy of the model.
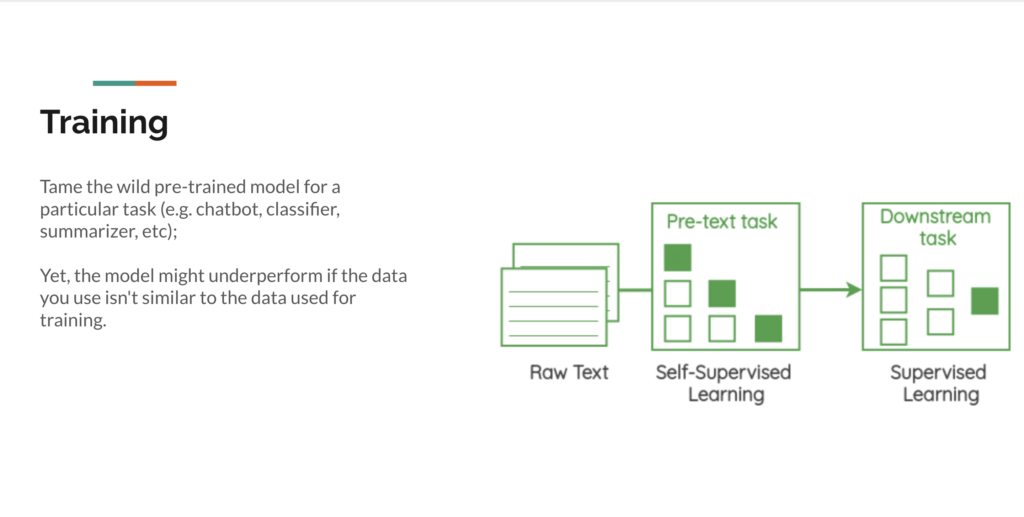
Then, the training stage can begin. This is when the model is given its rules, instructions, and tasks. This can be to classify, summarise, or as a chatbot assistant. However, the pre-training data should align with the task at hand. If not, hallucinations may occur and the AI may underperform. It is therefore essential to have an understanding of this to be able to identify the limitations of an AI model.
AIs unfortunately are mostly structured in a manner that does not necessarily benefit us as users. Currently, AI is often large, proprietary, for general purpose, cloud-based and one size fits all. Issues arise from many of these elements. The large aspect of these models means they are expensive to set and maintain. Additionally, basic technology which most citizens own, may not be able to accommodate the large functioning demand of the model. Furthermore, many of these models are black boxes. We also do not know what data is used, how the model is trained, or what data is extracted from the users. This element in particular makes it impossible to be able to assess the model to know if it working incorrectly or has internal biases.
To add to this, these models are often general-purpose, therefore, users may not be able to get the desired response that they seek. This can result in hallucinations, as we saw with the strawberry debacle, where a GPT wrongly stated that the word strawberry had only two ‘r’s rather than the correct three. As it is for general purpose, users may not be able to get the desired or specified outcomes. However, having smaller, more task-orientated AI can produce better quality outcomes. GPT4All is one open-source AI that allows you to implement Retrieval Augmented Generation (RAG) techniques that permit documents to be uploaded which acts as the foundation data in which your prompt or task can be performed. By having the ability to input your own data it allows the user to tailor the process.
Many of the AIs available use English language models. This excludes all people who do not speak English and excludes all data which is not in English. This then creates an AI narrative which is lacking diversity and global representation. Furthermore, exclusion continues as many AI functions use a cloud-based system. This prevents those that live in locations with unreliable internet or electricity from utilising these AI tools. Therefore, pivoting to localised and self-hosted AI can give such people access and stable usage.

AI may appear to be a saving grace for many, with the ability to simplify tasks but the outcomes are dependent on a multitude of factors including embedding, modeling, training, data and prompts. From the previous AI episode, we obtained skills to be able to identify AI-generated images but this episode has further this and presented a basic understanding of how AI functions which gives us the skills to assess the potential and limitations of AI. However, the structure of AI can and should be improved to be more accessible, representative, and adaptable which will result in higher-quality outcomes. This episode of the AI series presented a more critical eye on current AI tools and offered some open-source AI tools (listed below) which can be used to get around some of the current limitations of popular AI tools.
Watch the whole discussion:
Presenters
Adriano Belisario is a Data Journalist and Researcher who currently collaborates with the Joint Data Centre on Forced Displacement. He works to better use technology and data to address social concerns.
Eric Nitschke is founder and CEO of Wakoma . Eric’s focus is to facilitate the development of community-centred, open-source technologies.